Tối ưu kết quả trả về từ VectorDB với Scoring và Fingerprint | Xây dựng RAG AI

Giới thiệu
Trong hai phần trước của series Xây dựng RAG AI, chúng ta đã đi qua:
-
Phần 1: Tạo ứng dụng ASP.NET Core (.NET 8) và kết nối với OpenAI Chat Model.
-
Phần 2: Trang bị bộ nhớ cho RAG bằng Vector Database (Qdrant) với cơ chế lưu trữ embedding.
Đến Phần 3 này, chúng ta sẽ cùng nâng cấp khả năng tìm kiếm và truy vấn dữ liệu từ VectorDB. Nếu ở bài trước, hệ thống chỉ dừng lại ở mức “tìm được kết quả liên quan”, thì trong thực tế, chúng ta cần một bước quan trọng hơn: tối ưu hóa kết quả trả về để đảm bảo chính xác – gọn gàng – đáng tin cậy.
Những hạn chế khi chỉ tìm kiếm cơ bản trong VectorDB
Ở mức cơ bản, VectorDB trả về kết quả dựa trên độ tương đồng (similarity) giữa câu hỏi và embedding đã lưu. Tuy nhiên, trong ứng dụng thực tế, điều này có một số hạn chế:
-
Nhiễu – Có những kết quả tuy khớp vector nhưng lại không thực sự liên quan đến ngữ cảnh.
-
Dữ liệu trùng lặp – Có thể do nhập liệu nhầm hoặc dữ liệu bị lặp trong cơ sở.
-
Thiếu độ tin cậy – Kết quả không có trích nguồn, khiến người dùng khó kiểm chứng.
Chính vì vậy, việc chỉ “truy vấn và trả về” là chưa đủ. Chúng ta cần các kỹ thuật bổ sung.
Giải pháp tối ưu kết quả trong RAG AI
1. Lọc nhiễu bằng Scoring
-
Khi người dùng đưa ra câu hỏi, hệ thống sẽ tạo question vector và lấy ra danh sách các hits (kết quả).
-
Thay vì chấp nhận tất cả các hits trong Top K (ví dụ K=5), ta áp dụng thêm ngưỡng điểm (minimum score).
-
Ví dụ: chỉ giữ kết quả có score ≥ 0.25 hoặc 0.5.
-
Nếu tất cả dưới ngưỡng → trả về thông báo "không có kết quả phù hợp".
👉 Điều này giúp loại bỏ nhiễu, giữ lại các kết quả chất lượng và liên quan nhất.
2. Trích nguồn (Citation) để tăng tính minh bạch
-
Thay vì trả về một đoạn văn bản thuần túy, hệ thống sẽ bổ sung thêm:
-
Câu trả lời chính
-
Danh sách context (nguồn tham chiếu)
-
Ví dụ: câu trả lời AI đưa ra sẽ kèm link, tài liệu hoặc đoạn văn gốc đã được lấy từ VectorDB.
Điều này giúp người dùng tin tưởng hơn vì họ có thể kiểm chứng ngay tại nguồn.
3. Loại bỏ dữ liệu trùng lặp với Fingerprint
-
Trong thực tế, dữ liệu có thể bị nhập nhầm hoặc nạp nhiều lần, dẫn đến cùng một nội dung xuất hiện lặp lại khi truy vấn.
-
Giải pháp: sử dụng Fingerprint hoặc Hash để nhận diện và loại bỏ các bản ghi trùng lặp.
-
Nhờ đó, kết quả trả về sẽ sạch và tinh gọn, không gây khó chịu cho người dùng.
Triển khai kỹ thuật trong code
-
Refactor lại một số phần trong ứng dụng để dễ đọc và dễ quản lý hơn:
-
AppConfig,LMProvider,VectorPlanthay cho các tên cũ không rõ nghĩa.
-
-
Nguyên tắc clean code: “Tên dài còn hơn tên vô nghĩa”.
-
Xây dựng các hàm filter, dedup, và citation để tích hợp trực tiếp vào pipeline RAG.
Kết luận
Với Scoring, Fingerprint và Citation, hệ thống RAG AI không chỉ đơn giản là tìm kiếm dữ liệu mà đã tiến thêm một bước quan trọng:
-
Chính xác hơn nhờ lọc kết quả kém liên quan.
-
Đáng tin cậy hơn nhờ trích nguồn.
-
Gọn gàng hơn nhờ loại bỏ trùng lặp.
Đây chính là nền tảng để xây dựng một ứng dụng RAG AI mạnh mẽ và thực tế.
Trong Phần 4 của series, chúng ta sẽ tiếp tục đi sâu vào việc tích hợp thêm công cụ và tối ưu pipeline để hệ thống RAG AI trở nên linh hoạt và thông minh hơn.
Tags:
Bài viết liên quan

Nâng cấp RAG thành Agentic RAG với Dynamic Toolcall | Xây dựng RAG AI
Vậy làm thế nào để nâng cấp RAG thành một hệ thống Agentic RAG thông minh hơn, có khả năng tự động quyết định khi nào và nên gọi tool nào? Câu trả lời chính là Dynamic Toolcall.
Đọc thêm
Trang bị Memory cho RAG bằng Vector Database với Qdrant
Ở phần tiếp theo này, chúng ta sẽ tiến thêm một bước quan trọng: trang bị bộ nhớ (Memory) cho RAG bằng cách sử dụng Vector Database Qdrant.
Đọc thêm
Hướng dẫn tạo ứng dụng ASP.NET Core (.NET 8) và chuẩn bị kết nối OpenAI Chat Model để xây dựng RAG AI
Trong bài viết này, chúng ta sẽ bắt đầu một hành trình nhỏ: xây dựng một ứng dụng RAG AI (Retrieval-Augmented Generation).
Đọc thêm
Ra mắt khóa học: TEDU-53: Xây dựng ứng dụng CMS với ASP.NET Core 8.0 + Angular.
Ngay bây giờ các bạn có thể đăng ký thông qua mã giảm giá tại trang chi tiết khóa học. Mã giảm giá sẽ được vô hiệu hóa khi đủ số lượng người theo thang bậc.
Đọc thêm
10 thủ thuật để tăng tốc độ ứng dụng .NET Core 3.x
Trong bài viết này mình sẽ đưa ra 10 mẹo để giúp bạn tăng tốc ứng dụng ASP.NET Core 3.
Đọc thêm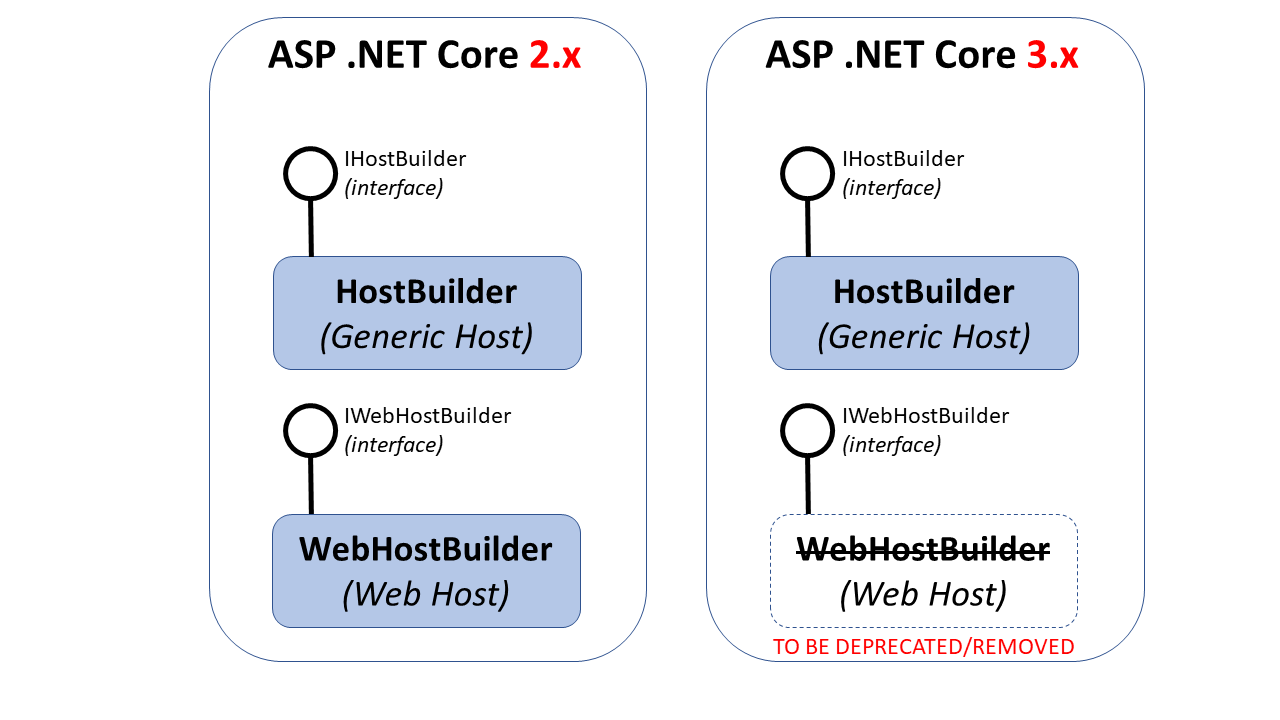
Migrate hệ thống ASP.NET Core 2.2 lên 3.1
Bài viết này mình đúc kết lại sau khi migrate toàn bộ hệ thống TEDU hiện tại từ .NET Core 2.2 lên 3.1 chia sẻ lại để mọi người cùng trao đổi
Đọc thêm
Tìm hiểu Unit Testing trong ASP.NET Core
Tiếp theo bài viết trước với tiêu đề Tìm hiểu về Dependency Injection trong ASP.NET Core. Hôm nay mình sẽ tập trung vào unit test.
Đọc thêm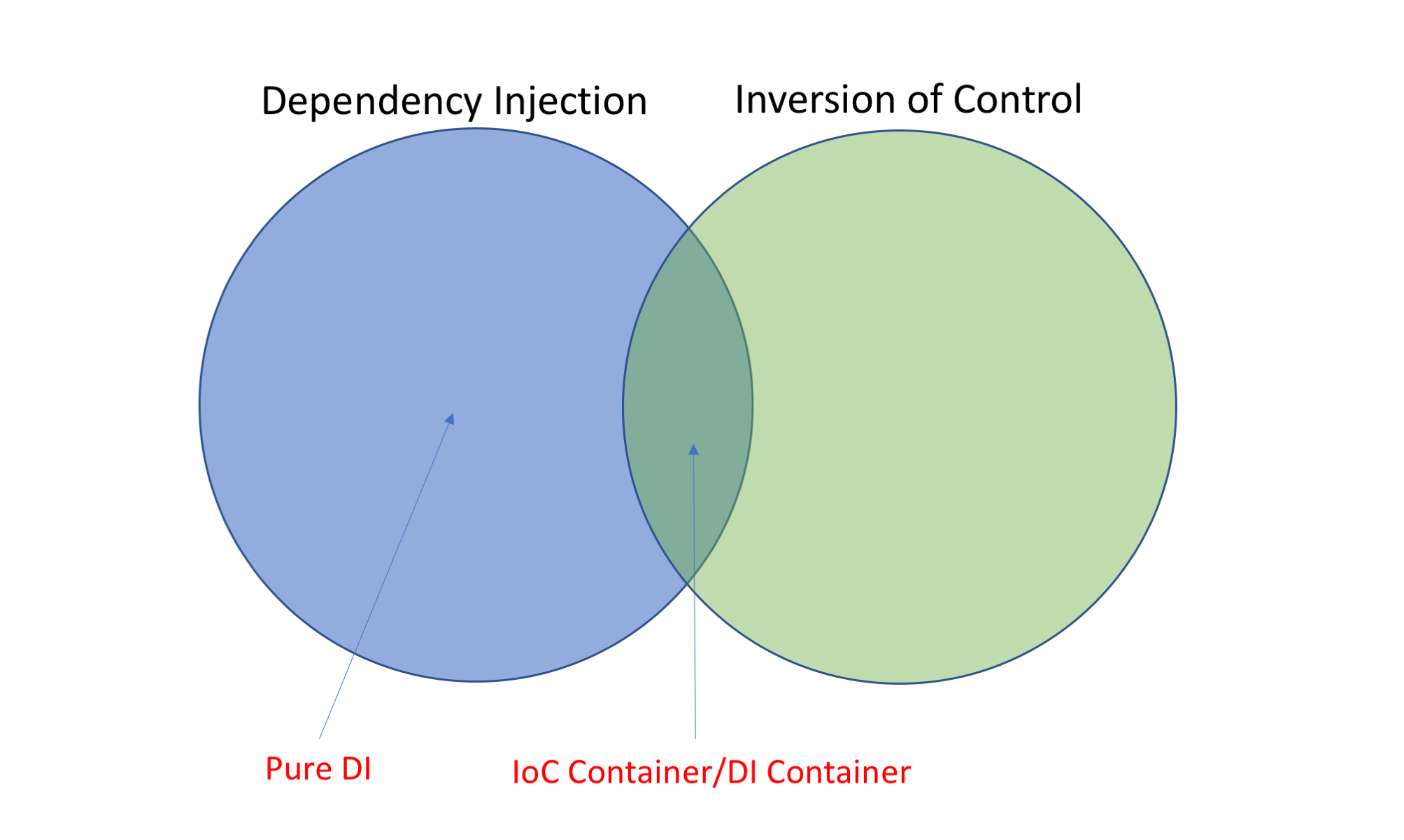
Tìm hiểu về Dependency Injection trong ASP.NET Core
Bài viết này chúng ta sẽ cùng tìm hiểu về những điều thú vị xung quanh depedency injection và unit testing.
Đọc thêm.jpg)
Cách sử dụng Yarn trong Visual Studio 2017
Cách sử dụng Yarn để quản lý các dependencies trong Visual Studio 2017
Đọc thêm
Cách dùng NPM trong ASP.NET Core thay vì Bower
Dùng Node Package Manager trong ASP.NET Core để quản lý các thư viện client thay vì Bower
Đọc thêm