TỔNG QUAN LÝ THUYẾT & THÀNH PHẦN CỐT LÕI SYSTEM DESIGN
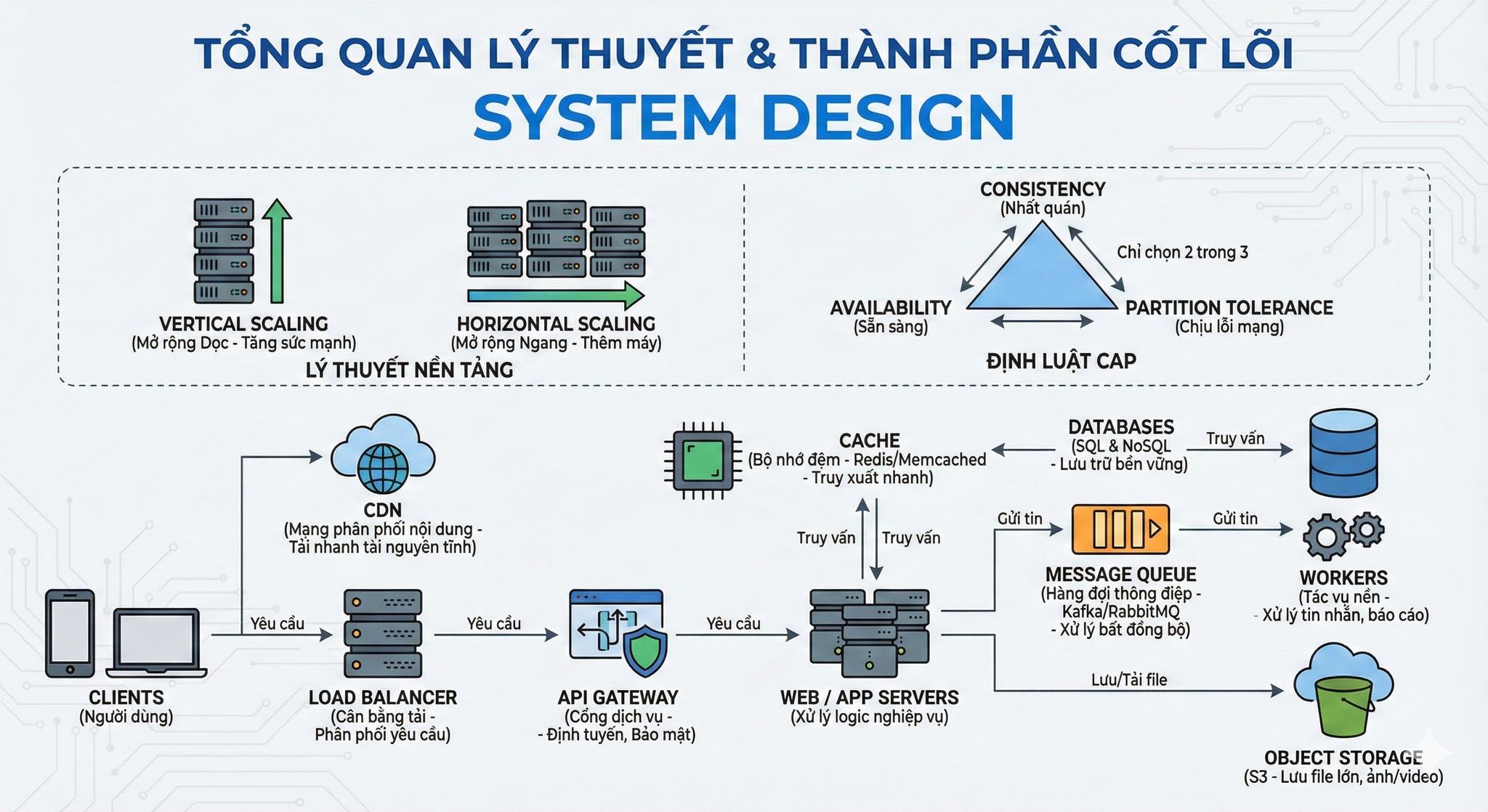
I. LÝ THUYẾT NỀN TẢNG
SCALING (Khả năng mở rộng):
Mô tả: Cách tăng cường năng lực xử lý của hệ thống để đáp ứng số lượng người dùng hoặc tải công việc ngày càng tăng.
Giải thích:
Vertical Scaling (Mở rộng dọc): Nâng cấp một máy chủ duy nhất mạnh hơn (thêm RAM, CPU). Giống như mua một chiếc máy tính có cấu hình cao hơn.
Horizontal Scaling (Mở rộng ngang): Thêm nhiều máy chủ nhỏ chạy song song. Giống như thay vì một chiếc máy tính siêu mạnh, bạn dùng 10 chiếc máy tính cấu hình vừa phải cùng làm việc. Đây là phương pháp phổ biến trong các hệ thống lớn.
Ví dụ: Một trang web bán hàng mùa sale có hàng triệu người truy cập. Thay vì nâng cấp 1 server thành siêu server (Vertical), họ thêm 10-20 server mới (Horizontal) để chia đều tải cho người dùng.
ĐỊNH LUẬT CAP:
Mô tả: Định luật này nói rằng trong một hệ thống phân tán, bạn chỉ có thể chọn tối đa 2 trong 3 yếu tố: Consistency (Nhất quán), Availability (Sẵn sàng), Partition Tolerance (Chịu lỗi mạng).
Giải thích:
Consistency (Nhất quán): Mọi người dùng đều thấy cùng một dữ liệu tại cùng một thời điểm. Dữ liệu luôn đúng.
Availability (Sẵn sàng): Hệ thống luôn hoạt động và trả về phản hồi (thành công hoặc lỗi) cho mọi yêu cầu.
Partition Tolerance (Chịu lỗi mạng): Hệ thống vẫn tiếp tục hoạt động ngay cả khi có lỗi về kết nối mạng giữa các thành phần của nó.
Trong các hệ thống phân tán (như sơ đồ này), P luôn được coi là bắt buộc. Do đó, ta thường phải đánh đổi giữa C và A.
Ví dụ:
CP (Nhất quán & Chịu lỗi): Hệ thống ngân hàng. Khi giao dịch chuyển tiền, dữ liệu phải tuyệt đối chính xác (C). Nếu đường truyền mạng giữa các server lỗi (P), hệ thống thà báo lỗi và từ chối giao dịch (hy sinh A tạm thời) còn hơn là để tiền bị nhân đôi hoặc mất mát.
AP (Sẵn sàng & Chịu lỗi): News Feed của Facebook. Khi một người đăng bài, dữ liệu có thể không hiển thị ngay lập tức cho tất cả bạn bè (hy sinh C tạm thời), nhưng bạn luôn có thể lướt News Feed và thấy bài mới (A cao).
II. CÁC THÀNH PHẦN CỐT LÕI (CORE COMPONENTS)
CLIENTS (Người dùng):
Mô tả: Các thiết bị hoặc ứng dụng mà người dùng cuối tương tác trực tiếp với hệ thống (điện thoại, máy tính, trình duyệt web).
Ví dụ: Ứng dụng Shopee trên điện thoại của bạn, trình duyệt Chrome khi bạn truy cập Google.
CDN (Content Delivery Network - Mạng phân phối nội dung):
Mô tả: Một mạng lưới các máy chủ đặt khắp nơi trên thế giới, dùng để lưu trữ và phân phối các nội dung tĩnh (ảnh, video, CSS, JS) tới người dùng từ vị trí gần nhất.
Giải thích: Giúp tăng tốc độ tải trang và giảm tải cho máy chủ chính.
Ví dụ: Khi bạn xem ảnh sản phẩm trên Lazada, ảnh đó không tải từ server chính ở Singapore mà từ server CDN ở Việt Nam hoặc quốc gia gần nhất, giúp ảnh hiện ra rất nhanh.
LOAD BALANCER (Cân bằng tải):
Mô tả: Thiết bị hoặc phần mềm phân phối các yêu cầu từ người dùng đến nhiều máy chủ (Web/App Servers) khác nhau để tránh quá tải cho một server.
Giải thích: Đảm bảo tính sẵn sàng cao và khả năng mở rộng bằng cách chia đều công việc.
Ví dụ: Khi một trang web có 1 triệu lượt truy cập, Load Balancer sẽ chia đều các yêu cầu này cho 10 máy chủ web thay vì dồn hết vào một máy chủ.
API GATEWAY (Cổng giao tiếp):
Mô tả: Một điểm truy cập duy nhất cho các API của hệ thống. Nó xử lý xác thực, định tuyến yêu cầu, giới hạn tốc độ và quản lý truy cập cho các dịch vụ khác.
Giải thích: Giúp quản lý và bảo mật các truy cập vào hệ thống, đặc biệt với kiến trúc Microservices.
Ví dụ: Khi ứng dụng di động của bạn gọi một API để lấy thông tin sản phẩm, API Gateway sẽ kiểm tra bạn có quyền truy cập không, sau đó chuyển yêu cầu đến đúng dịch vụ xử lý thông tin sản phẩm.
WEB / APP SERVERS (Máy chủ Web/Ứng dụng) / MICROSERVICES:
Mô tả: Nơi chứa logic kinh doanh chính của ứng dụng. Chúng nhận yêu cầu từ Load Balancer/API Gateway, xử lý dữ liệu và gửi phản hồi.
Giải thích: Kiến trúc Microservices chia nhỏ ứng dụng thành nhiều dịch vụ nhỏ, độc lập, giúp dễ phát triển, triển khai và mở rộng.
Ví dụ:
Một server xử lý việc đăng nhập người dùng.
Một server khác xử lý việc thêm sản phẩm vào giỏ hàng.
Một microservice chuyên tính toán giá khuyến mãi.
CACHE (Bộ nhớ đệm - Redis / Memcached):
Mô tả: Một lớp lưu trữ dữ liệu tạm thời tốc độ cao, thường nằm giữa server và database. Nó lưu các dữ liệu thường xuyên được truy cập.
Giải thích: Giảm tải cho database và tăng tốc độ phản hồi của hệ thống. Dữ liệu trong Cache có thể không phải lúc nào cũng mới nhất (hy sinh C để có A).
Ví dụ: Danh sách các sản phẩm bán chạy hoặc thông tin người dùng hay truy cập được lưu trong Cache. Khi bạn mở app, chúng hiện ra ngay mà không cần truy vấn Database.
DATABASE CLUSTER (Cơ sở dữ liệu):
Mô tả: Nơi lưu trữ vĩnh viễn và có tổ chức tất cả dữ liệu của hệ thống. Thường được chia thành các cụm (cluster) để đảm bảo tính sẵn sàng và khả năng mở rộng.
Giải thích:
SQL (Relational): Dữ liệu có cấu trúc chặt chẽ, quan hệ giữa các bảng rõ ràng (MySQL, PostgreSQL). Phù hợp cho dữ liệu giao dịch tài chính, thông tin người dùng, đơn hàng. Đảm bảo tính nhất quán cao.
NoSQL (Non-relational): Dữ liệu linh hoạt hơn, không yêu cầu cấu trúc cố định (MongoDB, Cassandra). Phù hợp cho dữ liệu lớn, log, giỏ hàng, hồ sơ người dùng phức tạp. Thường ưu tiên tính sẵn sàng và khả năng mở rộng hơn.
Ví dụ: MySQL lưu thông tin sản phẩm, giá cả, số lượng tồn kho. MongoDB lưu lịch sử tìm kiếm của người dùng hoặc các bài đánh giá sản phẩm.
MESSAGE QUEUE (Hàng đợi thông điệp - Kafka / RabbitMQ):
Mô tả: Một hệ thống giúp các thành phần của hệ thống giao tiếp với nhau một cách không đồng bộ. Các tác vụ cần xử lý sau được đưa vào hàng đợi.
Giải thích: Giúp hệ thống phản hồi nhanh cho người dùng, trong khi các tác vụ nặng (mà không cần phản hồi ngay) được xử lý ở chế độ nền. Giúp hệ thống chịu tải tốt hơn khi có nhiều yêu cầu đột ngột.
Ví dụ: Khi bạn đặt hàng, hệ thống báo "Đặt hàng thành công" ngay lập tức. Việc gửi email xác nhận, cập nhật kho, tính điểm thưởng được đưa vào Message Queue và xử lý sau.
WORKER SERVICES (Dịch vụ xử lý nền):
Mô tả: Các dịch vụ chuyên biệt chạy ngầm, liên tục lấy các tác vụ từ Message Queue và xử lý chúng.
Giải thích: Thực hiện các tác vụ nặng, tốn thời gian mà không ảnh hưởng đến trải nghiệm người dùng trên giao diện chính.
Ví dụ: Một Worker Service lấy thông báo "Có đơn hàng mới" từ Message Queue, sau đó gửi email xác nhận cho khách hàng, gửi thông báo cho shipper, cập nhật trạng thái đơn hàng trong Database.
OBJECT STORAGE (Lưu trữ đối tượng - S3):
Mô tả: Dịch vụ lưu trữ tệp tin lớn không có cấu trúc, như ảnh, video, tài liệu, file backup.
Giải thích: Khác với Database (lưu dữ liệu có cấu trúc), Object Storage tối ưu cho việc lưu trữ và truy xuất các file lớn.
Ví dụ: Tất cả hình ảnh sản phẩm, video quảng cáo trên một trang thương mại điện tử được lưu trữ trong Object Storage (như Amazon S3).
Tags:
Bài viết liên quan
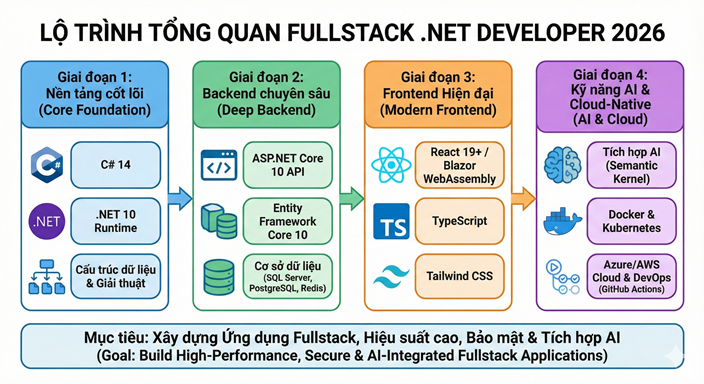
Lộ trình Fullstack .NET Developer 2026
Chào bạn, bước sang năm 2026, lộ trình của một Fullstack .NET Developer đã có những thay đổi quan trọng để thích nghi với sự lên ngôi của AI, điện toán đám mây và phiên bản .NET 10 (LTS) vừa ra mắt cuối năm 2025.
Đọc thêm
Cẩm nang Big-O: Thước đo hiệu năng thuật toán trong C#
Hiểu rõ Big-O từ O(1) đến O(n!) qua ví dụ C# thuần. Bí quyết tối ưu code, chọn đúng cấu trúc dữ liệu để hệ thống luôn chạy nhanh và ổn định.
Đọc thêm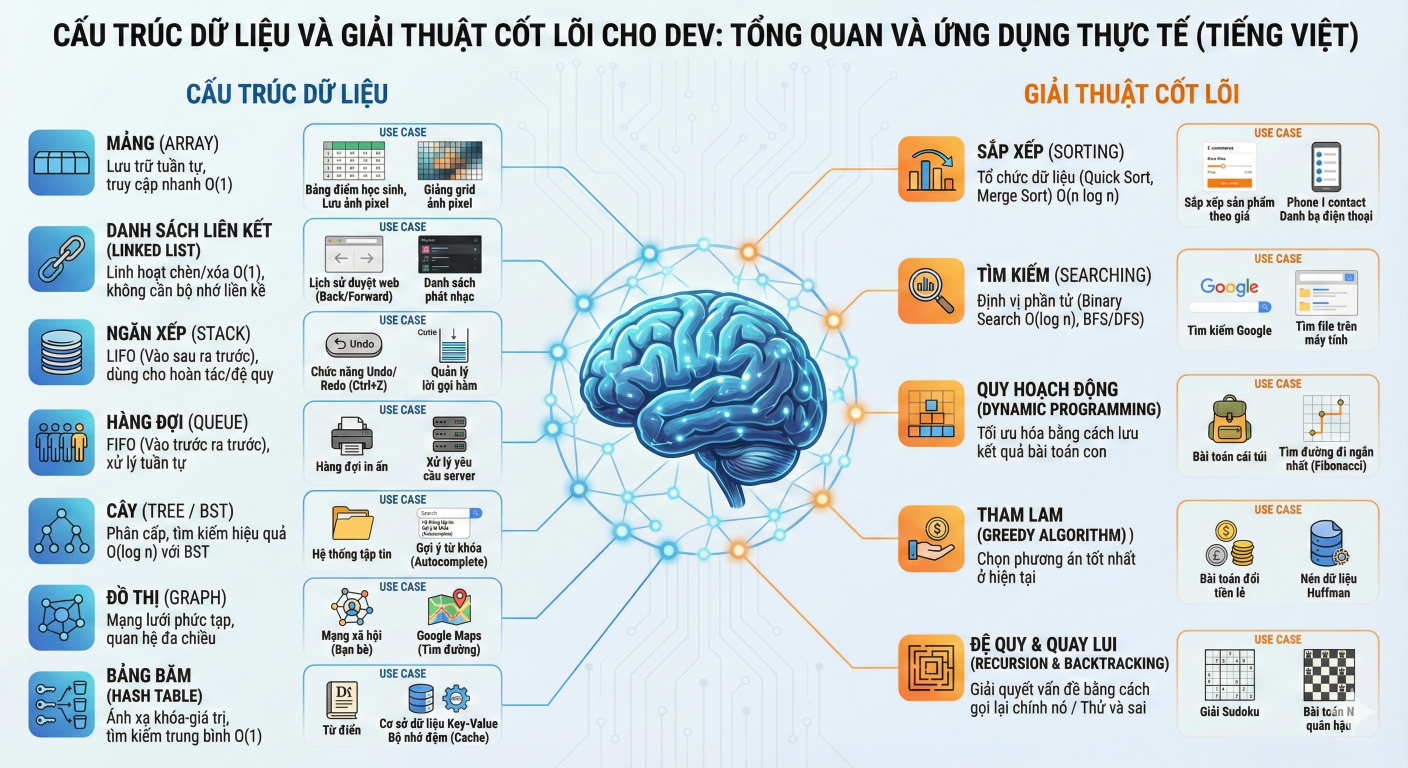
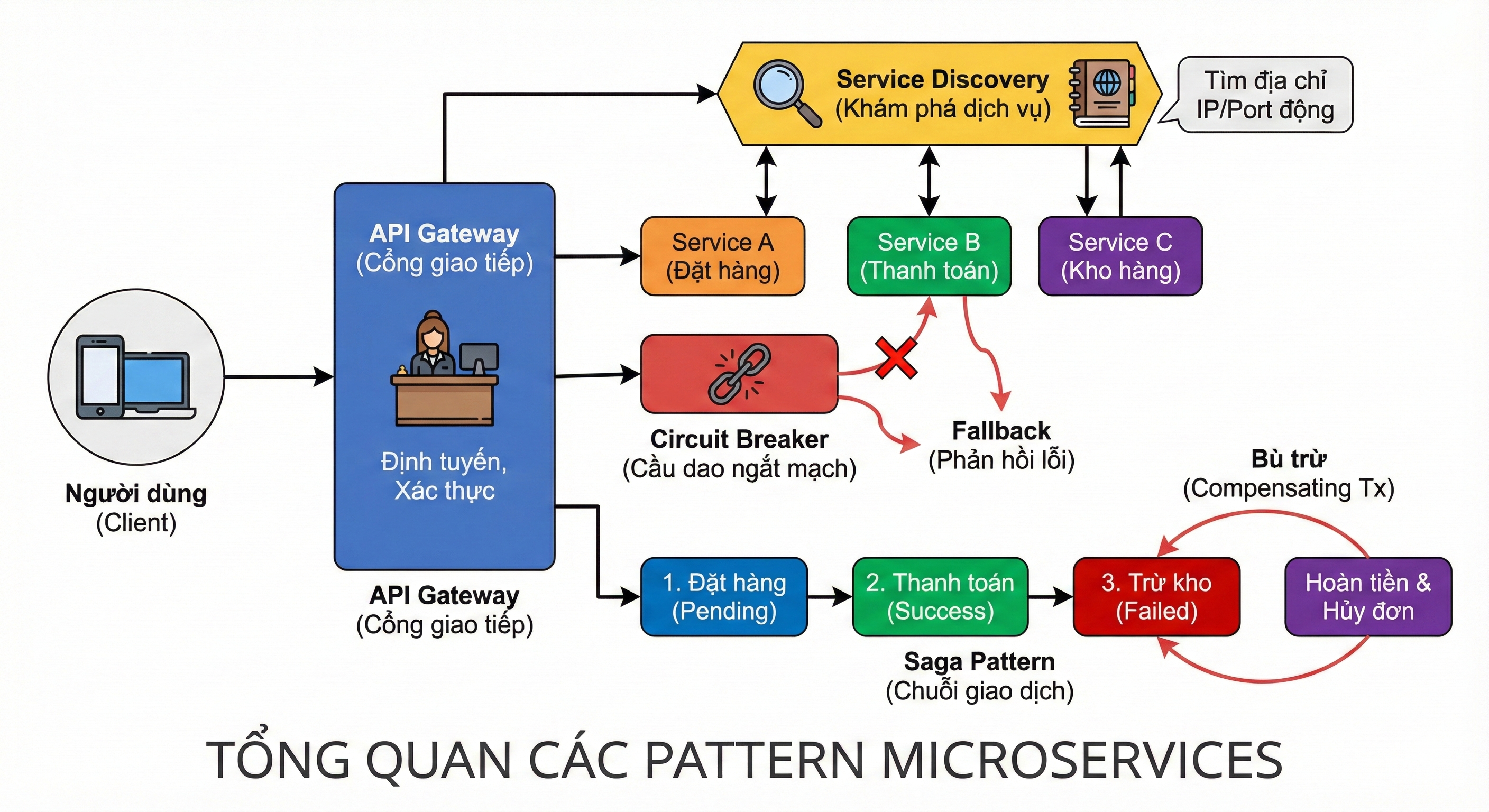
Các mẫu thiết kế (design patterns) phổ biến trong kiến trúc Microservices.
Các mẫu thiết kế (design patterns) phổ biến trong kiến trúc Microservices.
Đọc thêm
Hướng dẫn Bind Jenkins vào IIS trên Windows bằng Reverse Proxy
Cho phép truy cập Jenkins từ một subdomain (ví dụ jenkins.tedu.com.vn) thay vì phải gõ http://localhost:8080.
Đọc thêm
Hiểu về AI, LLM, RAG và Agentic RAG trong 15 phút
Trong vài năm gần đây, trí tuệ nhân tạo (AI) đã bùng nổ mạnh mẽ và trở thành tâm điểm của cả thế giới công nghệ. Nhưng đi kèm với nó là hàng loạt khái niệm mới như LLM, RAG, hay Agentic RAG khiến nhiều người mới bắt đầu cảm thấy lúng túng.
Đọc thêm
Hướng dẫn tự triển khai N8N trên CentOS bằng Docker Compose và NGINX
N8N là công cụ mã nguồn mở cho phép bạn tự động hóa quy trình làm việc (workflow automation) và tích hợp nhiều dịch vụ khác nhau mà không cần phải lập trình.
Đọc thêm
Hướng dẫn phân tích độ phức tạp thuật toán chi tiết
Độ phức tạp của giải thuật là một cách để đánh giá hiệu quả của một giải thuật dựa trên hai yếu tố chính là độ phức tạp thời gian và độ phức tạp không gian.
Đọc thêm
Bài 6. Các thao tác với XPath và Selector trong Selenium
Bài viết này hướng dẫn bạn làm việc XPath và Css Selector trong Selenium.
Đọc thêm
Bài 5. Các thao tác với Web Browser trong Selenium
Bài viết này hướng dẫn bạn làm việc sâu Web Browser trong Selenium.
Đọc thêm